
이전에 동아리 프로젝트를 진행하면서 구축한 서버리스 데이터파이프라인에 대해 정리해봤는데, 이번 글에서는 프로젝트를 통해서 배운 점들에 대해서 정리해보는 시간을 가지려고 합니다.
이전에 작성한 글을 아래에 링크 첨부합니다
서버리스(Serverless) 데이터 파이프라인 구축기
동아리 프로젝트에서 서버리스 서비스들을 이용해 데이터 파이프라인을 구축했습니다.이번 글에서는 어떤 데이터 파이프라인을 구축했는지, 왜 서버리스로 데이터파이프라인을 구축했는지에
itcodeheaven.tistory.com
1. 서버리스 서비스 불편함
첫번째로 배운 점은 서버리스 서비스를 이용하면서 몇가지 불편한 부분이 존재했습니다. 서버리스는 서버, 인프라의 확장과 유지보수를 클라우드(AWS)측에 전적으로 맡긴다는 장점이 있지만, 이런 장점 외에도 개인적으로 느낀 불편함은 다음과 같았습니다.
(1) 동시성 제약 조건이 존재
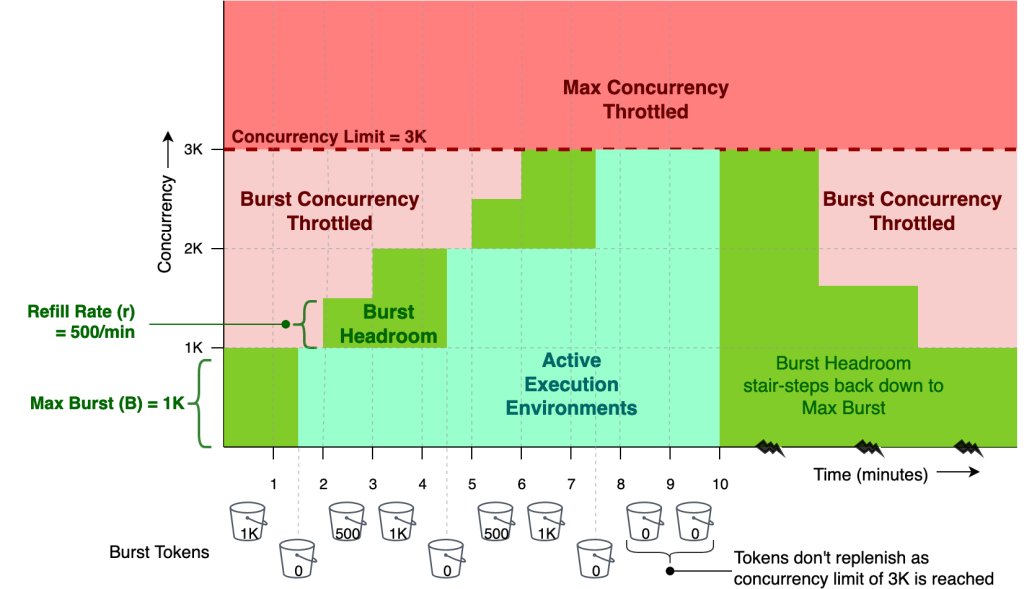
여러 Lambda를 활용해 크롤링 작업을 분산시켜서 진행했지만, Step Function 실행 중 어느 순간 Lambda에서 Too Many Requests Exception (429) 오류가 발생했습니다.
처음에는 크롤링 과정에서 발생한 문제이거나 웹사이트의 처리율 제한으로 인해 block 된거라고 생각해 코드를 수정하고, 타임아웃 설정을 조정했습니다. 그런데 이유를 찾아보니 AWS Lambda의 최대 동시성 제약 때문이였습니다. Lambda는 동시 실행에 최대 제한이 있어서, 이를 초과하면 요청이 스로틀링(429 오류)된다는 것을 알게 되었습니다.
Step Function의 Map State 앞단에 AWS SQS와 같이 Lambda의 동시성을 조절할 수 있는 서비스를 붙인다면 최대 동시성 제한 안에서 오류 없이 크롤링 할 수 있었을 것이라는 아쉬움이 남습니다.
(2) 디버깅의 어려움

Lambda와 Glue 실행 중 오류가 발생한 사이트와 코드 부분은 로그를 통해 확인할 수 있었지만, 구체적인 원인을 파악하는 것은 어려웠습니다. 서버리스 환경에서는 실제 코드가 실행되는 환경을 눈으로 직접 확인하기 어려웠습니다.
이전 글에도 적었듯 하나의 Lambda에서 여러 개의 탭을 활용하여 병렬 크롤링을 시도했지만, 클릭 버튼 조작이나 페이지 이동 시 Timeout 오류가 발생했을 때 해당 문제가 네트워크 성능 때문인지, Lambda의 프로세스 및 스레드 특성 때문인지 판단하기 어려웠던 이유도 실제 크롤링 진행 과정을 시각적으로 확인할 수 없었기 때문입니다.
그리고 한번 실행하는데 시간이 오래 걸려서, 한번 디버깅하는데 3~4분 걸리고 그러니깐 실제로 몇번 디버깅하고 실행하면 시간이 금방 지나갔습니다 ㅠㅠ
(3) 외부 라이브러리 사용의 불편함
Lambda나 Glue에서 외부 라이브러리를 사용하려면 직접 추가해야 합니다. 대부분의 라이브러리는 Lambda의 Layer를 쌓거나, s3에 package파일을 저장해서 정상적으로 적용되었지만, Playwright의 경우 설정이 원활하지 않았습니다. 여러 방법을 시도해 보았지만, 계속 라이브러리가 없다고 나왔습니다. (내가 잘못한거겠죠...)
여러 방법을 시도해보다가 Dockerfile에 "FROM mcr.microsoft.com/playwright/python:v1.21.0-focal as build-image"를 추가하여 정상적으로 실행할 수 있었습니다. EC2 환경에서는 단순히 Python을 설치하고 pip install만 하면 금방 해결될 문제였을 텐데 이런 점에서 서버리스 환경의 불편함을 체감했습니다.
2. 데이터의 최신성
프로젝트 서비스를 실제로 진행하면서 최신의 데이터를 사용자에게 제공하는 것이 중요하다는 것을 느꼈습니다.

저희 프로젝트의 경우에는 직접 가게로부터 데이터를 공급받는 것이 아니라 외부 플랫폼에서 데이터를 크롤링해 서비스를 진행했습니다. 따라서 음식점이 폐업했거나 이름이 변경된 경우를 확인하기 어려웠고, 이는 사용자에게 현실에 존재하지 않는 음식점을 추천하는 경우로 이어질 수 있다고 생각했습니다.
또한 크롤링을 통해 새로운 음식점 데이터를 수집했을 때, 기존 음식점의 이름이 변경된 것인지, 완전히 새로운 음식점인지 구분하기 어려운 경우가 생겼습니다. 단순히 새로운 데이터가 들어왔다고 무조건 추가하면 기존 데이터와 동일한 가게가 중복되는 문제가 발생할 가능성이 있었습니다.
따라서 저희 프로젝트에서는 데이터의 최신성을 보장하기위해 DB에 적재된 데이터를 주기적으로 검증하는 과정이 필요하다고 생각했습니다. 이를 위해 네이버 지도에서 음식점을 검색하여 폐업 여부 및 이름 변경을 정기적으로 확인하는 작업을 진행했습니다. 이 과정을 통해 음식점 데이터의 최신성을 확보하여, 사용자에게 실제 존재하는 음식점만을 추천하도록 개선할 수 있었습니다.
정리하며
프로젝트를 진행하면서 새로운 기술을 접하고, 실제 서비스 배포 및 운영까지 진행하면서 다양한 문제들에 대해서 고민했던 것 같습니다. 아직 실무 경험이 부족하기 때문에 실제 기업 환경에서는 이러한 문제들을 어떻게 해결하고 있을지 궁금합니다. 컨퍼런스 참여나 다양한 분들과의 교류를 통해 해당 문제들을 더 좋게 해결할 수 있는 방법들에 대해서 알게 되면 해당 글을 계속 수정해보도록 하겠습니다~!!
'데이터엔지니어링' 카테고리의 다른 글
| Github Actions를 이용한 ECR, ECS 배포 자동화하기 (2) (0) | 2025.03.16 |
|---|---|
| Github Actions를 이용한 ECR, ECS 배포 자동화하기 (1) (1) | 2025.03.16 |
| 서버리스(Serverless) 데이터 파이프라인 구축기 (2) | 2025.01.31 |
| [데이터엔지니어링] Docker 개념 (3) | 2024.05.03 |
| [데이터엔지니어링] Apache Kafka Connect 설명 (2) | 2024.04.13 |